Diligent writing refers to the process of consistently and carefully putting in the time and effort to write high-quality content. This can be achieved by establishing a routine, conducting thorough research, and editing and proofreading meticulously. Learn how to become a diligent writer and create compelling content.
Support Vector Machine (SVM) adalah sebuah model ML multifungsi yang dapat digunakan untuk klasifikasi linier dan non-linier, regresi, dan bahkan pada pendeteksian outlier.
SVM adalah salah satu metode yang paling populer dalam machine learning. Siapa pun yang tertarik untuk masuk ke dalam dunia ML, perlu mengetahui SVM.
Rekomendasi atau sistem rekomendasi adalah salah satu implementasi machine learning yang kita pakai hampir setiap hari.
Contohnya pada saat kita belanja daring, terdapat jutaan pilihan produk pada platform tersebut. Akan membuang banyak waktu jika kita harus melihat semua opsi tersebut. Sistem rekomendasi memiliki peran penting untuk membantu kita menemukan produk yang benar-benar kita cari.
Selain pada platform belanja daring, sistem rekomendasi juga hadir dalam aplikasi yang kita pakai sehari-hari seperti Youtube dan Spotify yang merekomendasikan video dan lagu yang menarik perhatian kita.
Nah, setelah mengetahui berbagai model machine learning, kita paham bahwa setiap dataset dan kasus memiliki pendekatan model yang berbeda. Kelas pengenalan ini hanya akan membahas 2 model machine learning yang paling umum yaitu classification dan regresi
Pada latihan ini kita akan menggunakan logistic regression untuk memprediksi apakah seseorang akan membeli setelah melihat iklan sebuah produk. Dataset untuk latihan bisa Anda unduh pada tautan berikut.
Seperti biasa, setelah kita mengunggah berkas data pada Colab kita akan mengubah dataset menjadi dataframe Pandas. Jangan lupa juga untuk mengimpor library dasar.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing importStandardScaler
df = pd.read_csv('Social_Network_Ads.csv')
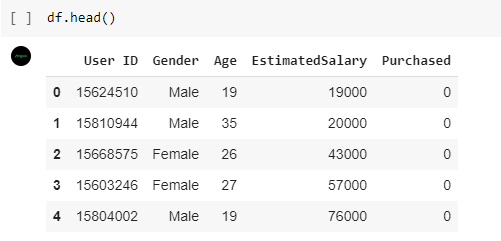
Pada cell selanjutnya gunakan fungsi head() pada dataframe untuk melihat 5 baris pertama dari dataset.
df.head()
Hasil dari fungsi df.head() seperti di bawah ini.
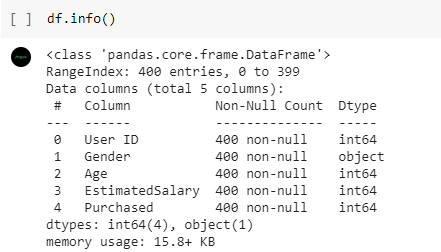
Kita juga perlu melihat apakah ada nilai yang kosong pada setiap atribut dengan menggunakan fungsi info(). Dapat dilihat bahwa nilai pada semua kolom sudah lengkap.
df.info()
Sedangkan tampilan hasil dari fungsi df.info() sebagai berikut.
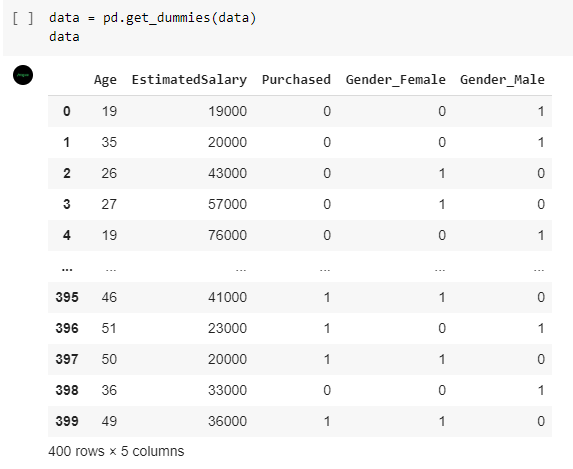
Pada dataset terdapat kolom ‘User ID’. Kolom tersebut merupakan atribut yang tidak penting untuk dipelajari oleh model sehingga perlu dihilangkan. Untuk menghilangkan kolom dari dataframe, gunakan fungsi drop.
data = df.drop(columns=['User ID'])
data = pd.get_dummies(data)
data
Ketika kode di atas dijalankan hasilnya seperti di bawah ini.
Jangan lupa untuk membagi data menjadi train set dan test set yang dapat dilakukan dengan fungsi train_test_split yang disediakan SKLearn.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
Setelah membagi data, kita buat model dengan membuat sebuah objek logistic regression. Setelah model dibuat, kita bisa melatih model kita dengan train set menggunakan fungsi fit().
from sklearn import linear_model
model = linear_model.LogisticRegression()
model.fit(X_train, y_train)
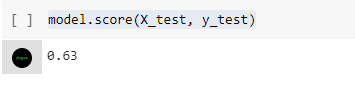
Setelah model dilatih, kita bisa menguji akurasi model pada test set dengan memanggil fungsi score() pada objek model.
Jenis kategori selanjutnya adalah regression. Tahukah Anda apa itu regression atau regresi? Regresi adalah salah satu teknik ML yang mirip dengan klasifikasi. Bedanya, pada klasifikasi sebuah model ML memprediksi sebuah kelas, sedangkan model regresi memprediksi bilangan kontinu. Bilangan kontinu adalah bilangan numerik.
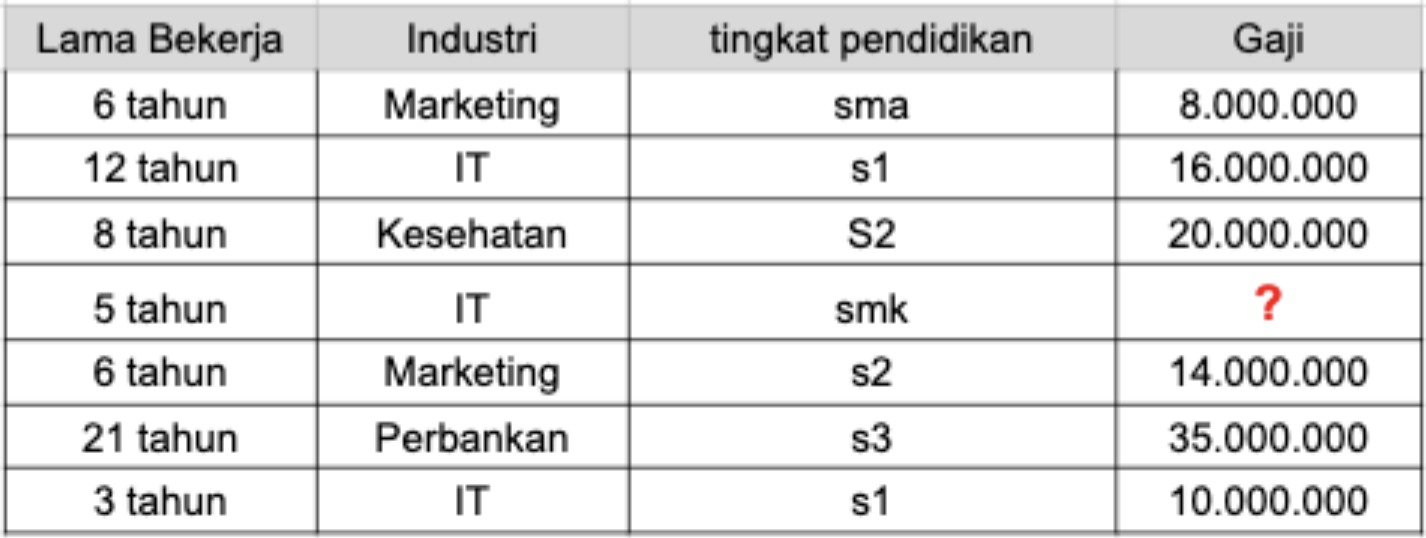
Jadi model klasifikasi memprediksi kelas atau kategori, dan model regresi memprediksi sebuah nilai berdasarkan atribut yang tersedia. Agar lebih paham, perhatikan contoh di bawah.
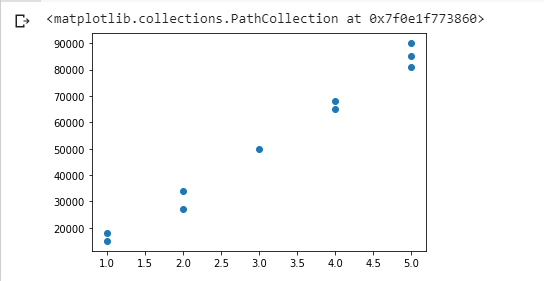
Pada contoh data di atas, model regresi akan memprediksi gaji berdasarkan atribut lama bekerja, industri, dan tingkat pendidikan. Gaji adalah contoh dari bilangan kontinu, di mana gaji tak memiliki kategori-kategori yang terbatas.
Pada submodul ini, jenis regresi yang akan dibahas adalah regresi linier. Selain regresi linier terdapat juga jenis regresi lain seperti regresi polinomial, lasso regression, stepwise regression dan sebagainya. Untuk penjelasan dari jenis-jenis regression yang ada, kunjungi tautan berikut.
Linear Regression
Regresi linier adalah salah satu metode supervised yang masuk dalam golongan regression, sesuai namanya. Contoh paling terkenal dari regresi linier adalah memperkirakan harga rumah berdasarkan fitur yang terdapat pada rumah seperti luas rumah, jumlah kamar tidur, lokasi dan sebagainya. Ini adalah model paling sederhana yang perlu diketahui guna memahami metode machine learning lain yang lebih kompleks. Regresi linier cocok dipakai ketika terdapat hubungan linear pada data. Namun untuk implementasi pada kebanyakan kasus, ia kurang direkomendasikan. Sebabnya, regresi linier selalu mengasumsikan ada hubungan linier pada data, padahal tidak.
Secara sederhana regresi linear adalah teknik untuk memprediksi sebuah nilai dari variable Y (variabel dependen) berdasarkan beberapa variabel tertentu X (variabel independen) jika terdapat hubungan linier antara X dan Y.
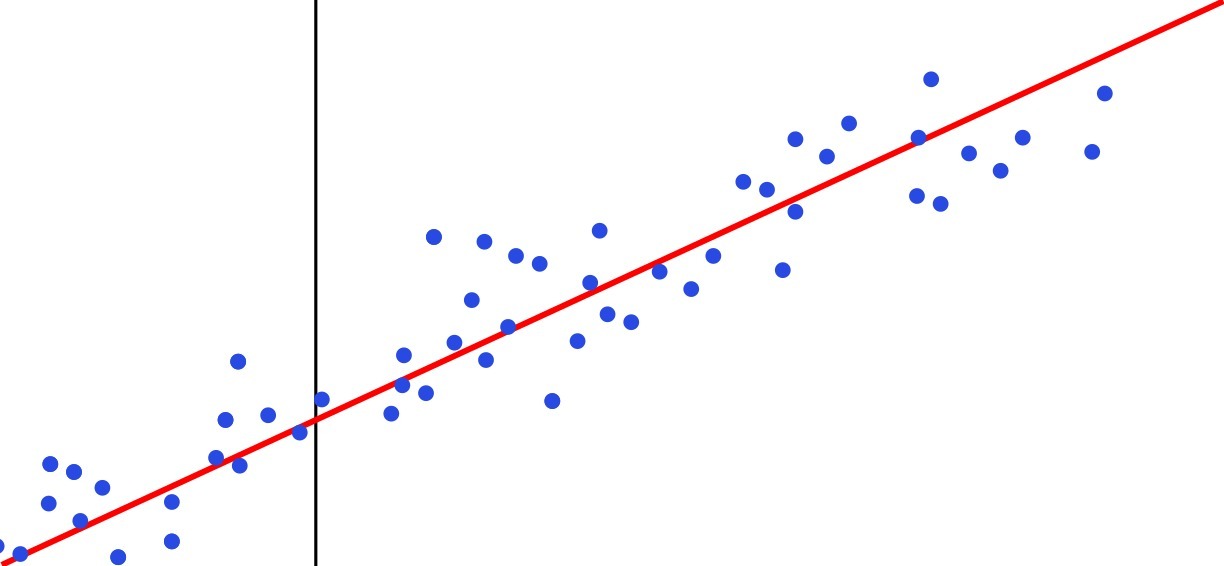
Hubungan antara hubungan linier dapat direpresentasikan dengan sebuah garis lurus (disebut garis regresi). Ilustrasi hubungan linier dapat dilihat pada gambar di mana data-data cenderung memiliki pola garis lurus.
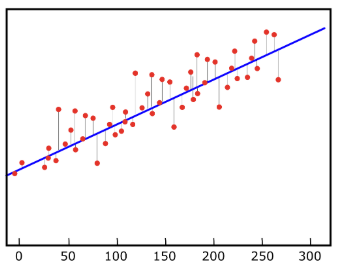
Ketika sebuah garis regresi digambar, beberapa data akan berada pada garis regresi dan beberapa akan berada di dekat garis tersebut. Sebabnya, garis regresi adalah sebuah model probabilistik dan prediksi kita adalah perkiraan. Jadi tentu akan ada eror/penyimpangan terhadap nilai asli dari variabel Y. Pada gambar di bawah, garis merah yang menghubungkan data-data ke gari regresi merupakan eror. Semakin banyak eror, menunjukkan bahwa model regresi itu belum optimal.
Logistic Regression
Setelah sebelumnya Anda mengenal regresi linier untuk masalah regresi, ada juga model seperti logistic regression, terlepas dari namanya merupakan sebuah model yang dapat digunakan untuk klasifikasi.
Logistic regression regression dikenal juga sebagai logit regression, maximum-entropy classification, dan log-linear classification merupakan salah satu metode yang umum digunakan untuk klasifikasi. Pada kasus klasifikasi, logistic regression bekerja dengan menghitung probabilitas kelas dari sebuah sampel.
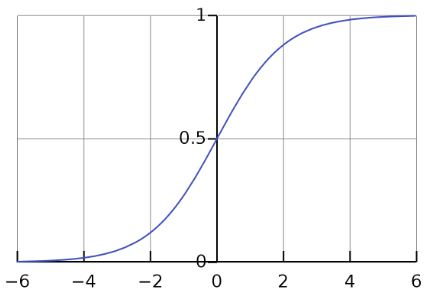
Sesuai namanya, logistic regression menggunakan fungsi logistik seperti di bawah untuk menghitung probabilitas kelas dari sebuah sampel. Contohnya sebuah email memiliki probabilitas 78% merupakan spam maka email tersebut termasuk dalam kelas spam. Dan jika sebuah email memiliki <50% probabilitas merupakan spam, maka email tersebut diklasifikasikan bukan spam.
Selanjutnya kita bisa mencoba menampilkan data tersebut dalam bentuk scatter plot. Jumlah kamar pada sumbu X adalah variabel independen dan harga rumah pada sumbu Y adalah variabel dependen.
# menampilkan scatter plot dari dataset
%matplotlib inline
plt.scatter(bedrooms, house_price)
Tampilan dari kode tersebut sebagai berikut.
Lalu pada cell berikutnya, kita bisa mulai melatih model kita dengan memanggil fungsi LinearRegression.fit() pada data kita.
from sklearn.linear_model importLinearRegression
bedrooms = bedrooms.reshape(-1,1)
linreg =LinearRegression()
linreg.fit(bedrooms, house_price)
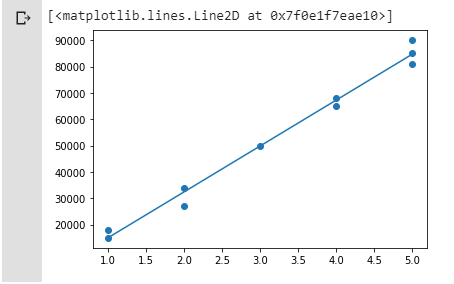
Terakhir kita bisa melihat bagaimana model kita menyesuaikan dengan data yang kita miliki dengan membuat plot dari model kita.
plt.scatter(bedrooms, house_price)
plt.plot(bedrooms, linreg.predict(bedrooms))
Hasilnya sebagai seperti di bawah ini
Model regresi linier adalah salah satu model machine learning yang paling sederhana. Model ini memiliki kompleksitas rendah dan bekerja sangat baik pada dataset yang memiliki hubungan linier. Jadi, ketika Anda menemui masalah yang terlihat memiliki hubungan linier, regresi linier dapat menjadi pilihan pertama sebagai model untuk dikembangkan
Kode program yang akan diajarkan di sini bisa diunduh di tautan berikut ini, untuk membukanya upload berkasnya dari Google Colab.
Pada sub modul latihan ini, kita akan menggunakan data yang lebih kompleks dari sebuah numpy array. Untuk coding practice kali ini kita akan memakai dataset Iris, salah satu dataset paling populer yang dipakai dalam belajar ML.
Dataset iris terdiri dari 4 atribut yaitu panjang sepal, lebar sepal, panjang petal, dan lebar petal. Terdapat 3 kelas target pada dataset ini. Data ini dipakai untuk masalah klasifikasi, di mana kita bisa memprediksi spesies dari sebuah bunga berdasarkan atribut-atribut yang diberikan.
Pertama kita akan mengimpor library yang dibutuhkan dan mempersiapkan dataset. Dataset dapat anda unduh di tautan berikut. Setelah data diunduh, masukkan berkas Iris.csv ke dalam Colab. Lalu jangan lupa konversi dataset menjadi dataframe Pandas.
from sklearn.tree importDecisionTreeClassifier
import pandas as pd
from sklearn.datasets import load_iris
iris = pd.read_csv('Iris.csv')
Untuk melihat informasi mengenai data, Anda bisa memanggil fungsi .head() pada dataframe.
iris.head()
Tampilan iris.head() saat dijalankan sebagai berikut.
Dapat dilihat bahwa terdapat kolom yang tidak penting pada dataset yaitu kolom ‘Id’. Untuk menghilangkan kolom tersebut kita bisa menggunakan fungsi drop().
iris.drop('Id',axis=1,inplace=True)
Selanjutnya kita pisahkan antara atribut dan label untuk pelatihan model kita.
X = iris[['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm']]
y = iris['Species']
Kemudian buat model decision tree kita. Terakhir kita melatih model kita dengan menggunakan fungsi fit(). Keluaran dari cell di bawah menunjukkan bahwa model decision tree telah dilatih dan parameter-parameternya juga ditampilkan. Penjelasan mengenai parameter akan dibahas di modul-modul selanjutnya.
# membuat model Decision Tree
tree_model =DecisionTreeClassifier()
# melakukan pelatihan model terhadap data
tree_model.fit(X, y)
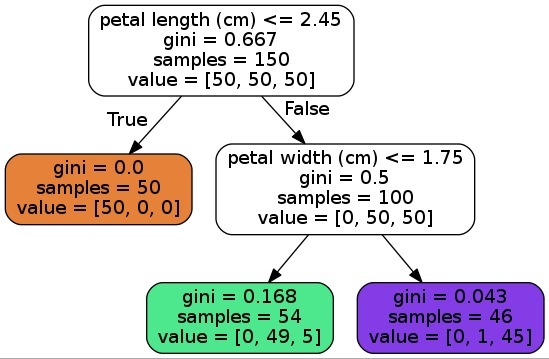
Kita bisa mencoba model yang telah kita buat untuk memprediksi spesies dari sebuah bunga Iris. Masih ingat bukan, bahwa atribut yang menjadi masukan dari model adalah panjang sepal, lebar sepal, panjang petal, dan lebar petal. Kita masukkan nilai yang sesuai dengan format tersebut secara berurutan dalam satuan centimeter. Pada kode di bawah kita ingin memprediksi spesies dari sebuah bunga iris yang memiliki panjang sepal 6,2 centimeter, lebar sepal 3,4 centimeter, panjang petal 5,4 centimeter, dan lebar petal 2,3 centimeter. Hasil prediksi dari model kita adalah virginica.
Jika kode tersebut dijalankan, maka tampilannya seperti di bawah ini.
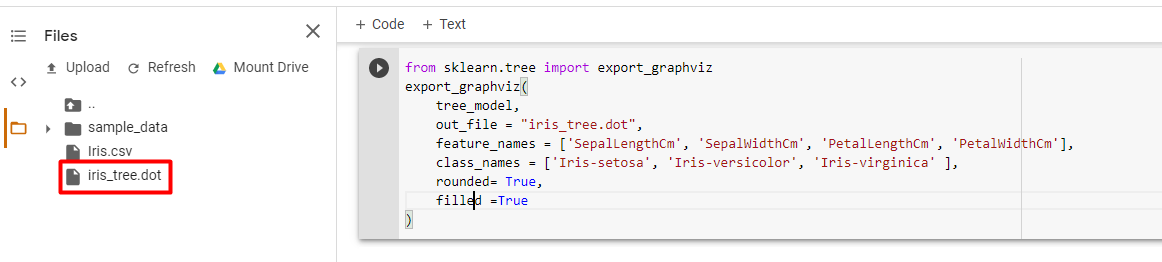
Kita juga bisa melihat visualisasi dari decision tree yang kita buat terhadap data dengan menggunakan library Graphviz. Hasil dari graphviz adalah dot file yang akan muncul pada folder file pada panel di kiri Colab.
Setelah berhasil dijalankan, hasil dari iris_tree.dot terlihat seperti di bawah ini.
Untuk melihat visualisasi decision tree kita bisa mengkonversi dot file ke dalam file png. Untuk mengunduh berkas iris_tree.dot pada gambar di atas, kita dapat melakukan klik kanan pada berkas tersebut dan mengunduhnya. Untuk konversi berkas dengan ekstensi dot menjadi berkas png dapat dilakukan di situs https://convertio.co/id/dot-png/.
Selamat! Anda telah berhasil membuat sebuah model decision tree untuk klasifikasi spesies bunga Iris. Anda juga telah berhasil menguji model anda untuk memprediksi spesies dari sebuah bunga iris. Untuk belajar lebih mendalam tentang decision tree, kunjungi tautan berikut yah




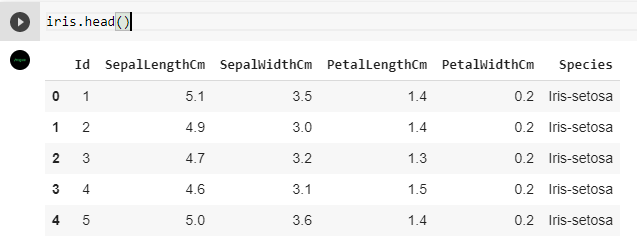 Dapat dilihat bahwa terdapat kolom yang tidak penting pada dataset yaitu kolom ‘Id’. Untuk menghilangkan kolom tersebut kita bisa menggunakan fungsi
Dapat dilihat bahwa terdapat kolom yang tidak penting pada dataset yaitu kolom ‘Id’. Untuk menghilangkan kolom tersebut kita bisa menggunakan fungsi