Pada submodul sebelumnya kita telah belajar bagaimana menggunakan test set untuk mengevaluasi model sebelum masuk ke tahap produksi.
Sekarang bayangkan ketika kita bertugas untuk mengembangkan sebuah proyek ML. Kita bimbang dalam memilih model yang akan dipakai, katakanlah dari 10 jenis model yang tersedia.
Salah satu opsinya adalah dengan melatih kedua model tersebut lalu membandingkan tingkat erornya pada test set. Setelah membandingkan kedua model, Anda mendapati model regresi linier memiliki tingkat eror yang paling kecil katakanlah sebesar 5%. Anda lalu membawa model tersebut ke tahap produksi.
Kemudian ketika model diuji pada tahap produksi, tingkat eror ternyata sebesar 15%. Kenapa ini terjadi?. Masalah ini disebabkan karena kita mengukur tingkat eror berulang kali pada test set.
Kita secara tidak sadar telah memilih model yang hanya bekerja dengan baik pada test set tersebut. Hal ini menyebabkan model tidak bekerja dengan baik ketika menemui data baru. Solusi paling umum dari masalah ini adalah dengan menggunakan validation set.
Train test validation set
Validation set atau holdout validation adalah bagian dari train set yang dipakai untuk pengujian model pada tahap awal. Secara sederhana, kita menguji beberapa model dengan hyperparameter yang berbeda pada data training yang telah dikurangi data untuk validation. Lalu kita pilih model serta hyperparameter yang bekerja paling baik pada validation set. Setelah proses pengujian pada holdout validation, kita bisa melatih model menggunakan data training yang utuh (data training termasuk data validation) untuk mendapatkan model final. Terakhir kita mengevaluasi model final pada test set untuk melihat tingkat erornya.
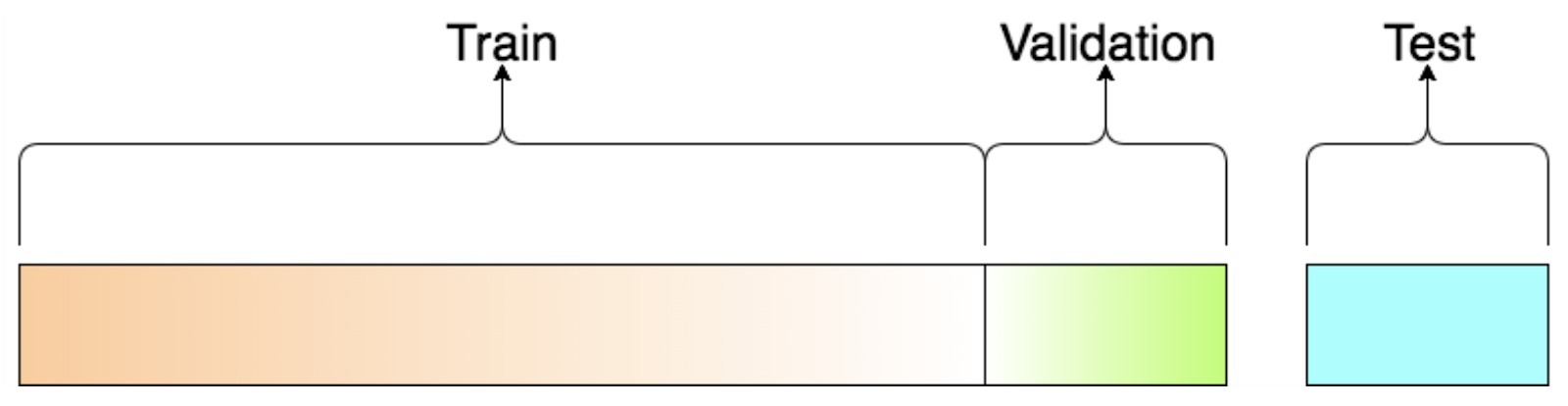
Dalam menggunakan holdout validation, ada beberapa hal yang harus dipertimbangkan. Jika ukuran validation set-nya terlalu kecil, maka ada kemungkinan kita memilih model yang tidak optimal. Ketika ukuran validation set terlalu besar, maka sisa data pada train set lebih kecil dari data train set utuh di mana kondisi ini tidak ideal untuk membandingkan model yang berbeda pada data training yang lebih kecil. Solusi untuk masalah ini adalah dengan menggunakan Cross Validation.
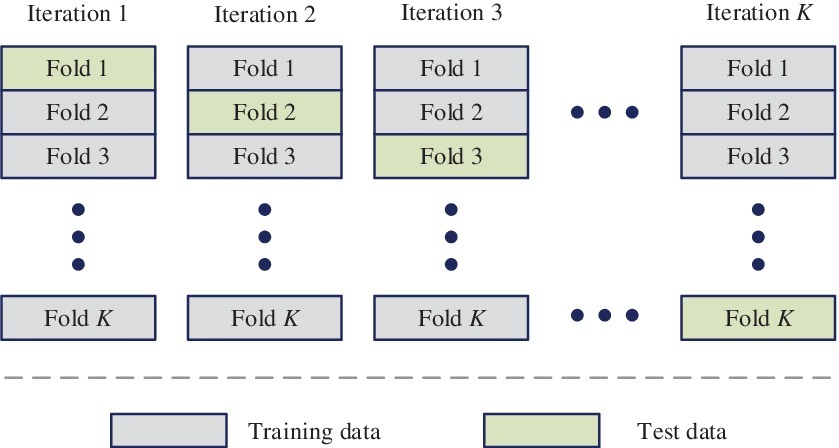
Cross validation
K-Fold Cross Validation atau lebih sering disebut cross validation adalah salah satu teknik yang populer dipakai dalam evaluasi model ML. Pada cross validation, dataset dibagi sebanyak K lipatan. Pada setiap iterasi, setiap lipatan akan dipakai satu kali sebagai data uji dan lipatan sisanya dipakai sebagai data latih. Dengan menggunakan cross validation kita akan dapat hasil evaluasi yang lebih akurat karena model dievaluasi dengan seluruh data. Berikut adalah ilustrasi dari cross validation