
Setelah dataset dibersihkan masih ada beberapa tahap yang perlu dilakukan agar dataset benar-benar siap untuk diproses oleh model machine learning.
Umumnya beberapa model machine learning tidak dapat mengolah data kategorik, sehingga kita perlu melakukan konversi data kategorik menjadi data numerik. Data kategorik adalah data yang berupa kategori dan berjenis string. Contoh data kategorik adalah sebuah kolom pada dataset yang berisi jenis binatang seperti anjing, kucing, dan harimau.
Contoh lain dari data kategorik adalah merek mobil seperti Ford, Honda, Toyota, dan BMW.
Banyak model machine learning seperti Regresi Linear dan Support Vector Machine (kedua model ini akan dibahas pada modul-modul selanjutnya) yang hanya menerima input numerik sehingga tidak bisa memproses data kategorik. Salah satu teknik untuk mengubah data kategorik menjadi data numerik adalah dengan menggunakan One Hot Encoding. One Hot Encoding mengubah data kategorik dengan membuat kolom baru untuk setiap kategori seperti gambar di bawah.
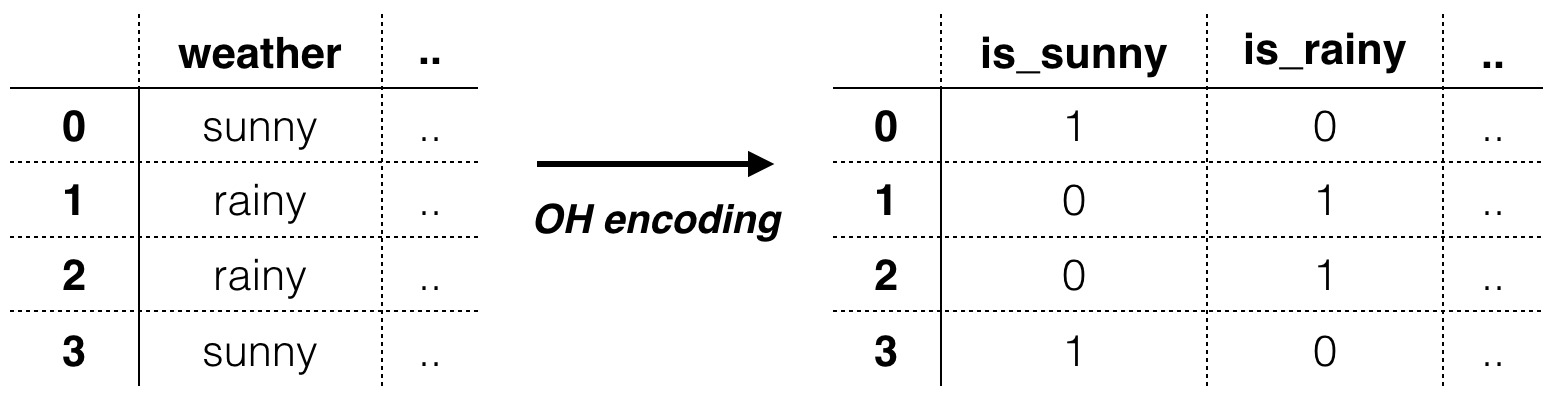
Data Preparation Opsional
Selain konversi data kategorik menjadi numerik, ada beberapa teknik lain dalam data preparation. Teknik yang akan dibahas antara lain membuang outlier, normalization, dan standardization.
Outlier Removal
Dalam statistik, outlier adalah sebuah nilai yang jauh berbeda dari kumpulan nilai lainnya dan dapat mengacaukan hasil dari sebuah analisis statistik. Outlier dapat disebabkan kesalahan dalam pengumpulan data atau nilai tersebut benar ada dan memang unik dari kumpulan nilai lainnya.
Apapun alasannya kemunculannya, Anda perlu mengetahui cara untuk mengidentifikasi dan memproses outlier. Ini adalah bagian penting dalam persiapan data di dalam machine learning. Salah satu cara termudah untuk mengecek apakah terdapat outlier dalam data kita adalah dengan melakukan visualisasi.
Berikut adalah contoh visualisasi terhadap data yang memiliki outlier.
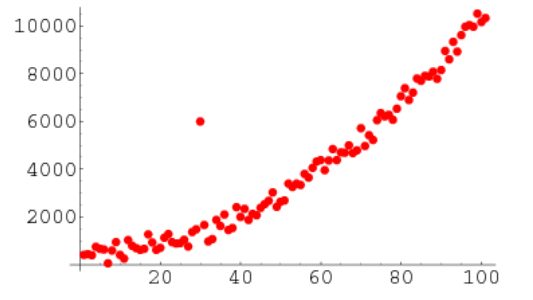
Dapat dilihat dengan jelas bahwa terdapat satu sampel yang jauh berbeda dengan sampel-sampel lainnya. Setelah mengetahui bahwa di data kita terdapat outlier, kita dapat mencari lalu menghapus sampel tersebut dari dataset.
Normalization
Normalization adalah salah satu teknik yang dipakai dalam data preparation. Tujuan dari normalisasi adalah mengubah nilai-nilai dari sebuah fitur ke dalam skala yang sama. Normalization memungkinkan kenaikan performa dan stabilitas dari sebuah model machine learning.
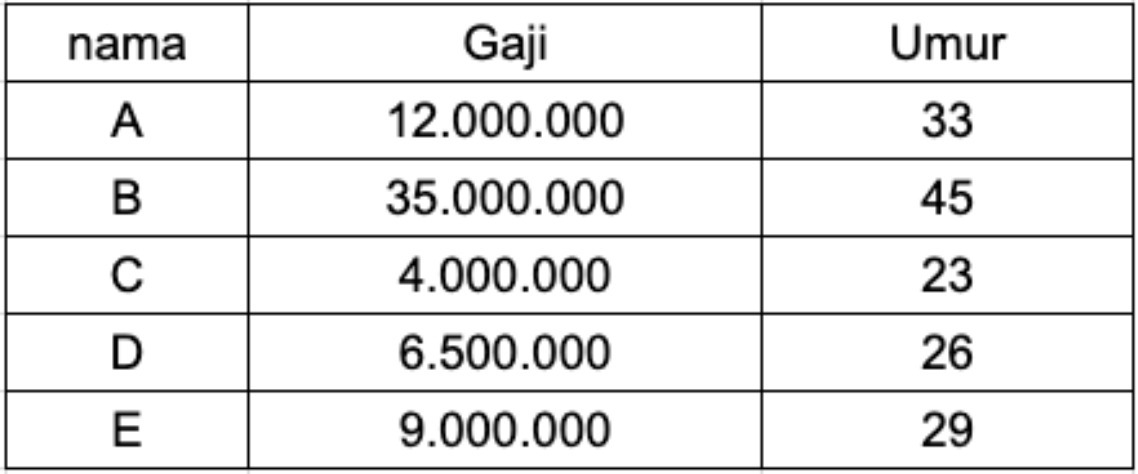
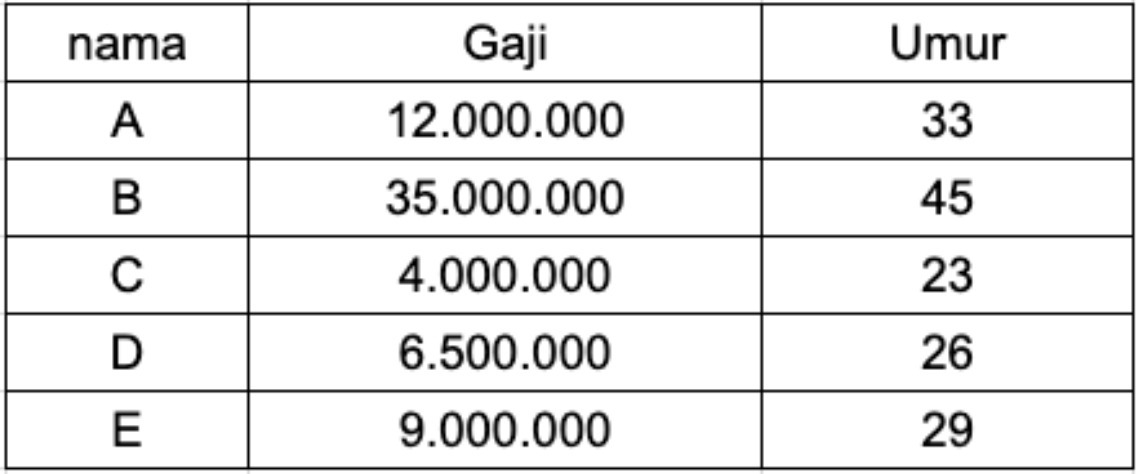
Contoh dari normalization adalah ketika kita memiliki dataset seperti di atas yang memiliki fitur umur dengan skala 23 sampai 45 tahun, dan fitur penghasilan dengan skala 4.000.000 sampai 35.000.000. Di sini kita melihat bahwa fitur penghasilan sekitar satu juta kali lebih besar dari fitur umur dan menunjukkan kedua fitur ini berada pada skala yang sangat jauh berbeda.
Ketika membangun model seperti regresi linear, fitur penghasilan akan sangat mempengaruhi prediksi dari model karena nilainya yang jauh lebih besar daripada umur. Walaupun, tidak berarti fitur tersebut jauh lebih penting dari fitur umur.
Salah satu contoh dari normalization adalah min-max scaling di mana nilai-nilai dipetakan ke dalam skala 0 sampai 1. SKLearn menyediakan library untuk normalization
Pada Colab kita Import library MinMaxScaler dan masukkan data dari tabel sebelumnya.
- from sklearn.preprocessing import MinMaxScaler
- data = [[12000000, 33], [35000000, 45], [4000000, 23], [6500000, 26], [9000000, 29]]
Pada cell selanjutnya kita buat object scaler dan panggil fungsi fit() pada data. Fungsi fit adalah fungsi untuk menghitung nilai minimum dan maksimum pada tiap kolom.
- scaler = MinMaxScaler()
- scaler.fit(data)
Apabila dijalankan maka hasilnya sebagai berikut.

Terakhir kita panggil fungsi transform yang akan mengaplikasikan scaler pada data.
- print(scaler.transform(data))
Hasil dari kode di atas seperti berikut.

Setiap nilai dari kolom gaji dan umur telah dipetakan pada skala yang sama seperti di bawah ini.
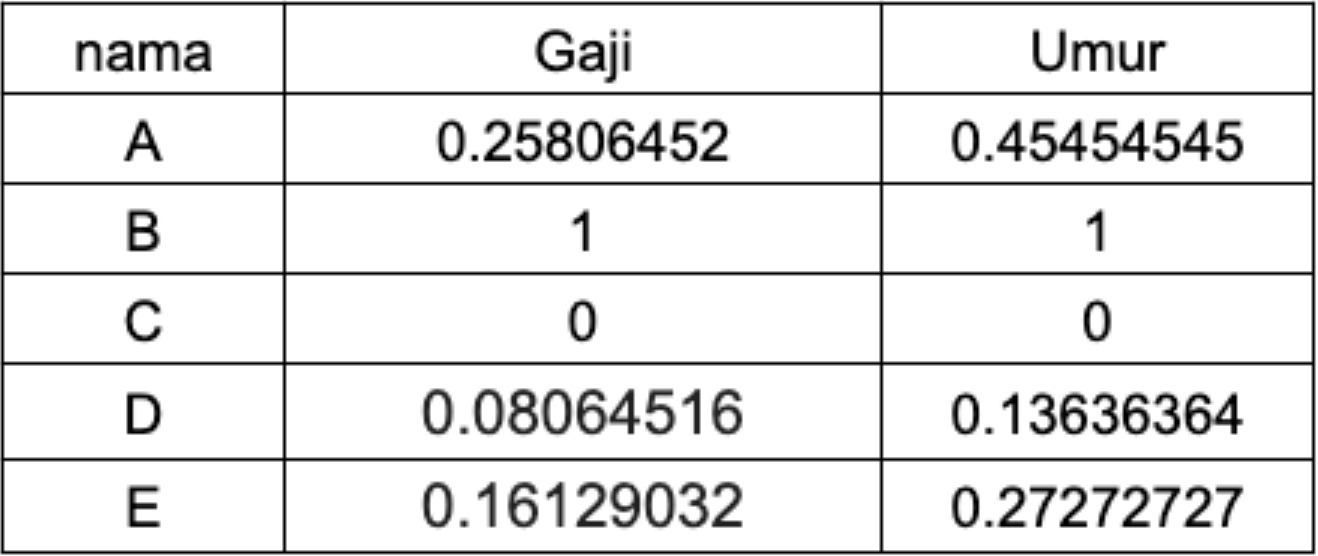
Untuk informasi lebih detail tentang Min Max Scaler, silakan Anda kunjungi tautan berikut.
Standardization
Standardization adalah proses untuk konversi nilai-nilai dari suatu fitur sehingga nilai-nilai tersebut memiliki skala yang sama. Z score adalah metode paling populer untuk standardisasi di mana setiap nilai pada sebuah atribut numerik akan dikurangi dengan rata-rata dan dibagi dengan standar deviasi dari seluruh nilai pada sebuah kolom atribut.
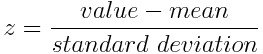
Fungsi standarisasi sama dengan normalization. Keduanya berfungsi menyamakan skala nilai dari tiap atribut pada data. SKLearn menyediakan library untuk mengaplikasikan standard scaler pada data.
Pada colab di cell pertama, kita akan mengimport library preprocessing dari scikit learn lalu membuat data dummy sesuai dengan tabel di atas.
- from sklearn import preprocessing
- data = [[12000000, 33], [35000000, 45], [4000000, 23], [6500000, 26], [9000000, 29]]
Selanjutnya kita buat object scaler dan panggil fungsi fit dari scaler pada data. Fungsi fit memiliki fungsi untuk menghitung rata-rata dan deviasi standar dari setiap kolom atribut untuk kemudian dipakai pada fungsi transform.
- scaler = preprocessing.StandardScaler().fit(data)
Terakhir, kita panggil fungsi transform untuk mengaplikasikan standard scaler pada data. Untuk melihat hasil dari standard scaler kita tinggal memanggil objek scaler yang telah kita buat sebelumnya. Kodenya sebagai berikut.
- data = scaler.transform(data)
- data
Hasil akhirnya apabila dijalankan seperti di bawah ini.

Untuk informasi lebih detail tentang standardization, silakan Anda kunjungi tautan berikut.